
今天來嘗試另外一個LSTM經典案例 - 股票預測,股票也是時間序列型資料!過去,金融業希望能找出一個強而有力的模型,不管預測股票或者期貨等等標的。但,似乎目前都還未有一個非常powerful的標的。也有可能有人已經做出來,只是不願意release,畢竟做出來 = 發大財。而針對金融相關標的的預測,以前看過一些paper以及方法。像是希望能利用情感分析等外部資訊來增加預測水準 (Ex: 輿情,最近股票市場可能跟川普發文有正相關吧XD )。因此,也可以利用上一篇情感分析的方法,來做為股票預測的特徵。現在許多人嘗試使用Deep Reinforcement Learning (DRL) 來預測股票,套一句李教授說的話 "硬train一發"。
這次使用的是台灣50的股票預測,台灣50就是一次幫你買進台灣最大的50檔股票 (Ex: TSMC),這些股票又稱為ETF。接下來就開始今天的實作。
首先可以直接讀資料看一下資料樣態
stock = pd.read_csv('stock50.csv')
stock.head()
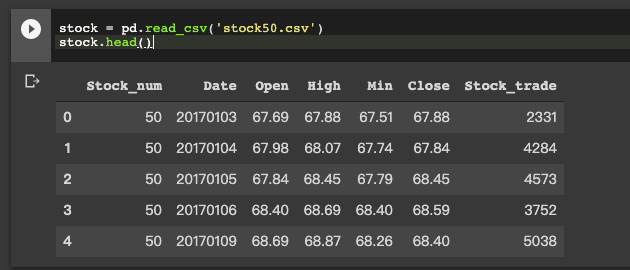
資料欄位包含了
| 資料欄位 | 內容 |
|---|---|
| Stock_num | 股票編號 |
| Date | 日期 |
| Open | 開盤價 |
| High | 最高價格 |
| Min | 最低價格 |
| Close | 收盤價格 |
| Stock_trade | 交易量 |
知道欄位後,接下來可以做一些前處理,Ex: Max - Min Normalize。此外,因為我們要預測的是收盤價格,所以會需要shit日期
def normalize(df):
norm = df.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
return norm
stock = stock.dropna()
stock['y'] = stock['Close'].shift(-1)
stock.iloc[:,2:4] = normalize(stock.iloc[:,2:4])
stock.head()
因為我們要針對時間序列資料做前處理,並做成可以預測的樣態 (Ex: 五天預測一天,或者十天預測一天)。
def train_windows(df, ref_day=5, predict_day=1):
X_train, Y_train = [], []
for i in range(df.shape[0]-predict_day-ref_day+1):
X_train.append(np.array(df.iloc[i:i+ref_day,:-1]))
Y_train.append(np.array(df.iloc[i+ref_day:i+ref_day+predict_day]["y"]))
return np.array(X_train), np.array(Y_train)
接下來就可以train一發了,上一篇我們是自己寫LSTM function,這次嘗試改用tf.keras.Sequential的方式來執行,就像是:
class stock_lstm(keras.Model):
def __init__(self,units):
super(stock_lstm, self).__init__()
self.rnn = Sequential([
layers.SimpleRNN(units,input_shape=(5,2),dropout=0.2,return_sequences=True,unroll=True),
layers.SimpleRNN(units,dropout=0.2,unroll=True)])
self.fc = layers.Dense(32)
self.out = layers.Dense(1)
def call(self, inputs, training=None):
x = self.rnn(inputs)
x = self.fc(x)
out = self.out(x)
return out
這樣是不是看起來很方便,且直觀,更像以前在使用 keras api 的方法!
接下來就可以直接model compile以及model.fit了!針對股票預測的部分,loss可以選擇MAE,MSE 等等 loss function,就不能選擇crossentropy的方法了!
rnn_model = stock_lstm(units)
rnn_model.compile(optimizer =keras.optimizers.Adam(),loss="mean_absolute_error",metrics=['mean_absolute_error'])
rnn_model.fit(data,epochs=epochs, validation_data = data_test,shuffle=True)
今天跑完LSTM的股票應用,以前研究所時,本魯也曾經在金融業實習過,當初所預測的標的是期貨相關產品 ,也很許多金融業前輩學習到很多。也很感謝當時後的長官,因為資料科學或是做模型真的很需要Domain Know how,當時候學到了許多基本的金融指標。感謝大家漫長閱讀~明天應該會來看一些新的模型!
請問一下使用 min max normalization 是否意味predict_y 之後要再denormalization?
有其它方式試合股票的normalization嗎?

